接上文:Go并发 - 并发原语Mutex、RWMutex
上文提到了关于Golang的两个基础并发原语Mutex、RWMutex,接下来我们来介绍下Golang中常见的几个并发原语和并发场景:
WaitGroup 基本用法 1 2 3 func (wg *WaitGroup) Add (delta int ) func (wg *WaitGroup) Done () func (wg *WaitGroup) Wait ()
Add,用来设置 WaitGroup 的计数值。
Done,用来将 WaitGroup 的计数值减 1,其实就是调用了 Add(-1)。
Wait,调用这个方法的 goroutine 会一直阻塞,直到 WaitGroup 的计数值变为 0。
example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 type Counter struct { mu sync.Mutex count uint64 } func (c *Counter) Incr () c.mu.Lock() c.count++ c.mu.Unlock() } func (c *Counter) Count () uint64 c.mu.Lock() defer c.mu.Unlock() return c.count } func worker (c *Counter, wg *sync.WaitGroup) defer wg.Done() time.Sleep(time.Second) c.Incr() } func main () var counter Counter var wg sync.WaitGroup wg.Add(10 ) for i := 0 ; i < 10 ; i++ { go worker(&counter, &wg) } wg.Wait() fmt.Println(counter.Count()) }
内部实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 type WaitGroup struct { noCopy noCopy state1 [3 ]uint32 } func (wg *WaitGroup) state () (statep *uint64 , semap *uint32 ) if uintptr (unsafe.Pointer(&wg.state1))%8 == 0 { return (*uint64 )(unsafe.Pointer(&wg.state1)), &wg.state1[2 ] } else { return (*uint64 )(unsafe.Pointer(&wg.state1[1 ])), &wg.state1[0 ] } }
noCopy 的辅助字段,主要就是辅助 vet 工具检查是否通过 copy 赋值(实际工程中也能使用这个技巧) 这个 WaitGroup 实例。
state1,一个具有复合意义的字段,包含 WaitGroup 的计数、阻塞在检查点的 waiter 数和信号量。因为对 64 位整数的原子操作要求整数的地址是 64 位对齐的,所以针对 64 位和 32 位环境的 state 字段的组成是不一样的。
Add方法逻辑: Add 方法主要操作的是 state 的计数部分。你可以为计数值增加一个 delta 值,内部通过原子操作把这个值加到计数值上。需要注意的是,这个 delta 也可以是个负数,相当于为计数值减去一个值,Done 方法内部其实就是通过 Add(-1) 实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 func (wg *WaitGroup) Add (delta int ) statep, semap := wg.state() state := atomic.AddUint64(statep, uint64 (delta)<<32 ) v := int32 (state >> 32 ) w := uint32 (state) if v > 0 || w == 0 { return } *statep = 0 for ; w != 0 ; w-- { runtime_Semrelease(semap, false , 0 ) } } func (wg *WaitGroup) Done () wg.Add(-1 ) }
Wait 方法的实现逻辑: 不断检查 state 的值。如果其中的计数值变为了 0,那么说明所有的任务已完成,调用者不必再等待,直接返回。如果计数值大于 0,说明此时还有任务没完成,那么调用者就变成了等待者,需要加入 waiter 队列,并且阻塞住自己。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func (wg *WaitGroup) Wait () statep, semap := wg.state() for { state := atomic.LoadUint64(statep) v := int32 (state >> 32 ) w := uint32 (state) if v == 0 { return } if atomic.CompareAndSwapUint64(statep, state, state+1 ) { runtime_Semacquire(semap) return } } }
Cond Cond并不常用,一般用在需要在唤醒一个或者所有的等待者做一些检查操作的时候(等待/通知(wait/notify)机制)。
基本用法 1 2 3 4 5 type Cond func NeWCond (l Locker) *Cond func (c *Cond) Broadcast () func (c *Cond) Signal () func (c *Cond) Wait ()
Signal : 允许调用者 Caller 唤醒一个等待此 Cond 的 goroutine。如果此时没有等待的 goroutine,显然无需通知 waiter;如果 Cond 等待队列中有一个或者多个等待的 goroutine,则需要从等待队列中移除第一个 goroutine 并把它唤醒。在其他编程语言中,比如 Java 语言中,Signal 方法也被叫做 notify 方法。调用 Signal 方法时,不强求你一定要持有 c.L 的锁。
Broadcast: 允许调用者 Caller 唤醒所有等待此 Cond 的 goroutine。如果此时没有等待的 goroutine,显然无需通知 waiter;如果 Cond 等待队列中有一个或者多个等待的 goroutine,则清空所有等待的 goroutine,并全部唤醒。在其他编程语言中,比如 Java 语言中,Broadcast 方法也被叫做 notifyAll 方法。同样地,调用 Broadcast 方法时,也不强求你一定持有 c.L 的锁。
Wait: 会把调用者 Caller 放入 Cond 的等待队列中并阻塞,直到被 Signal 或者 Broadcast 的方法从等待队列中移除并唤醒。
Cond包含一个Mutex对象作为参数,在使用时需要进行初始化操作。
example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 func main () c := sync.NewCond(&sync.Mutex{}) var ready int for i := 0 ; i < 10 ; i++ { go func (i int ) time.Sleep(time.Duration(rand.Int63n(10 )) * time.Second) c.L.Lock() ready++ c.L.Unlock() log.Printf("等待者#%d 已准备就绪\n" , i) c.Broadcast() }(i) } c.L.Lock() for ready != 10 { c.Wait() log.Println("等待者唤醒一次" ) } c.L.Unlock() log.Println("所有等待者都准备就绪" ) }
Once Once使用比较简单,一般在进行单例对象(如数据库链接、配置对象等)初始化时使用。
基本用法 当我们需要初始化单例对象时,可以通过定义package级别的变量或者在init、main函数开始执行的时候执行一个初始化函数,这些方式都是线程安全的,但很多时候我们需要进行延迟初始化 。
Once包含方法:
1 func (o *Once) Do (f func () )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package mainimport ( "fmt" "sync" ) func main () var once sync.Once f1 := func () fmt.Println("in f1" ) } once.Do(f1) f2 := func () fmt.Println("in f2" ) } once.Do(f2) }
因为当且仅当第一次调用 Do 方法的时候参数 f 才会执行,即使第二次、第三次、第 n 次调用时 f 参数的值不一样,也不会被执行,比如下面的例子,虽然 f1 和 f2 是不同的函数,但是第二个函数 f2 就不会执行。
典型使用场景:
cache初始化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func Default () *Cache defaultOnce.Do(initDefaultCache) return defaultCache } var ( defaultOnce sync.Once defaultCache *Cache ) func initDefaultCache () ...... defaultCache = c } var ( defaultDirOnce sync.Once defaultDir string defaultDirErr error )
测试用例初始化资源:
1 2 3 4 5 6 func ForceAusFromTZIForTesting () ResetLocalOnceForTest() localOnce.Do(func () }
内部实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 type Once struct { done uint32 m Mutex } func (o *Once) Do (f func () ) if atomic.LoadUint32(&o.done) == 0 { o.doSlow(f) } } func (o *Once) doSlow (f func () ) o.m.Lock() defer o.m.Unlock() if o.done == 0 { defer atomic.StoreUint32(&o.done, 1 ) f() } }
Once 实现要使用一个互斥锁,这样初始化的时候如果有并发的 goroutine,就会进入doSlow 方法。 互斥锁的机制保证只有一个 goroutine 进行初始化,同时利用双检查的机制(double-checking),再次判断 o.done 是否为 0,如果为 0,则是第一次执行,执行完毕后,就将 o.done 设置为 1,然后释放锁。
使用互斥锁主要是为了当参数f执行很慢时,后续调用Do方法的goroutine虽然看到 done 已经设置为执行过了,但是获取某些初始化资源的时候可能会得到空的资源,因为 f 还没有执行完。
map map在Go中是非线程安全的数据结构,在多个goroutine同时访问一个map对象时,程序会panic。
我们一般需要通过加锁的方式来实现一个线程安全的map。
采用读写锁来保护map 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 type RWMap struct { sync.RWMutex m map [int ]int } func NewRWMap (n int ) *RWMap return &RWMap{ m: make (map [int ]int , n), } } func (m *RWMap) Get (k int ) (int , bool ) m.RLock() defer m.RUnlock() v, existed := m.m[k] return v, existed } func (m *RWMap) Set (k int , v int ) m.Lock() defer m.Unlock() m.m[k] = v } func (m *RWMap) Delete (k int ) m.Lock() defer m.Unlock() delete (m.m, k) } func (m *RWMap) Len () int m.RLock() defer m.RUnlock() return len (m.m) } func (m *RWMap) Each (f func (k, v int ) bool ) m.RLock() defer m.RUnlock() for k, v := range m.m { if !f(k, v) { return } } }
分片加锁 采用RWMutex可以解决map线程不安全的问题,但在大量并发读写的情况下,性能较差,这里可以采用分片加锁的方式来实现细粒度加锁(https://github.com/orcaman/concurrent-map):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 var SHARD_COUNT = 32 type ConcurrentMap []*ConcurrentMapShared type ConcurrentMapShared struct { items map [string ]interface {} sync.RWMutex } func New () ConcurrentMap m := make (ConcurrentMap, SHARD_COUNT) for i := 0 ; i < SHARD_COUNT; i++ { m[i] = &ConcurrentMapShared{items: make (map [string ]interface {})} } return m } func (m ConcurrentMap) GetShard (key string ) *ConcurrentMapShared return m[uint (fnv32(key))%uint (SHARD_COUNT)] } func (m ConcurrentMap) Set (key string , value interface {}) shard := m.GetShard(key) shard.Lock() shard.items[key] = value shard.Unlock() } func (m ConcurrentMap) Get (key string ) (interface {}, bool ) shard := m.GetShard(key) shard.RLock() val, ok := shard.items[key] shard.RUnlock() return val, ok }
sync.Map sync.Map是Go的官方库中的实现,在使用上与标准的map类型有所区别,一般在以下场景下,sync.Map的性能会优于map+RWMutex:
只会增长的缓存系统中,一个 key 只写入一次而被读很多次。
多个 goroutine 为不相交的键集读、写和重写键值对。
sync.Map的基本使用 Store:用来设置一个键值对,或者更新一个键值对的。
Load:用来读取一个 key 对应的值。
Delete:用来删除一个key
sync.map 还有一些 LoadAndDelete、LoadOrStore、Range 等辅助方法,但是没有 Len 这样查询 sync.Map 的包含项目数量的方法,并且官方也不准备提供。如果你想得到 sync.Map 的项目数量的话,你可能不得不通过 Range 逐个计数。
sync.Map的实现 sync.Map主要的实现逻辑如下:
空间换时间。通过冗余的两个数据结构(只读的 read 字段、可写的 dirty),来减少加锁对性能的影响。对只读字段(read)的操作不需要加锁。
优先从 read 字段读取、更新、删除,因为对 read 字段的读取不需要锁。
动态调整。miss 次数多了之后,将 dirty 数据提升为 read,避免总是从 dirty 中加锁读取。
double-checking。加锁之后先还要再检查 read 字段,确定真的不存在才操作 dirty 字段。
延迟删除。删除一个键值只是打标记,只有在提升 dirty 字段为 read 字段的时候才清理删除的数据。
Map数据结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 type Map struct { mu Mutex // 基本上你可以把它看成一个安全的只读的map // 它包含的元素其实也是通过原子操作更新的,但是已删除的entry就需要加锁操作了 read atomic.Value // readOnly // 包含需要加锁才能访问的元素 // 包括所有在read字段中但未被expunged(删除)的元素以及新加的元素 dirty map[interface{}]*entry // 记录从read中读取miss的次数,一旦miss数和dirty长度一样了,就会把dirty提升为read,并把dirty置空 misses int } type readOnly struct { m map[interface{}]*entry amended bool // 当dirty中包含read没有的数据时为true,比如新增一条数据 } // expunged是用来标识此项已经删掉的指针 // 当map中的一个项目被删除了,只是把它的值标记为expunged,以后才有机会真正删除此项 var expunged = unsafe.Pointer(new(interface{})) // entry代表一个值 type entry struct { p unsafe.Pointer // *interface{} }
Store方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 func (m *Map) Store (key, value interface {}) read, _ := m.read.Load().(readOnly) if e, ok := read.m[key]; ok && e.tryStore(&value) { return } m.mu.Lock() read, _ = m.read.Load().(readOnly) if e, ok := read.m[key]; ok { if e.unexpungeLocked() { m.dirty[key] = e } e.storeLocked(&value) } else if e, ok := m.dirty[key]; ok { e.storeLocked(&value) } else { if !read.amended { m.dirtyLocked() m.read.Store(readOnly{m: read.m, amended: true }) } m.dirty[key] = newEntry(value) } m.mu.Unlock() } func (m *Map) dirtyLocked () if m.dirty != nil { return } read, _ := m.read.Load().(readOnly) m.dirty = make (map [interface {}]*entry, len (read.m)) for k, e := range read.m { if !e.tryExpungeLocked() { m.dirty[k] = e } }
Store 既可以是新增元素,也可以是更新元素。如果运气好的话,更新的是已存在的未被删除的元素,直接更新即可,不会用到锁。如果运气不好,需要更新(重用)删除的对象、更新还未提升的 dirty 中的对象,或者新增加元素的时候就会使用到了锁,这个时候,性能就会下降。
所以从这一点来看,sync.Map 适合那些只会增长的缓存系统(k8s operator的workpool就可以使用),可以进行更新,但是不要删除,并且不要频繁地增加新元素。
Load方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 func (m *Map) Load (key interface {}) (value interface {}, ok bool ) read, _ := m.read.Load().(readOnly) e, ok := read.m[key] if !ok && read.amended { m.mu.Lock() read, _ = m.read.Load().(readOnly) e, ok = read.m[key] if !ok && read.amended { e, ok = m.dirty[key] m.missLocked() } m.mu.Unlock() } if !ok { return nil , false } return e.load() } func (m *Map) missLocked () m.misses++ if m.misses < len (m.dirty) { return } m.read.Store(readOnly{m: m.dirty}) m.dirty = nil m.misses = 0 }
如果幸运的话,我们从 read 中读取到了这个 key 对应的值,那么就不需要加锁了,性能会非常好。但是,如果请求的 key 不存在或者是新加的,就需要加锁从 dirty 中读取。所以,读取不存在的 key 会因为加锁而导致性能下降,读取还没有提升的新值的情况下也会因为加锁性能下降。
其中,missLocked 增加 miss 的时候,如果 miss 数等于 dirty 长度,会将 dirty 提升为 read,并将 dirty 置空。
Delete方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 func (m *Map) LoadAndDelete (key interface {}) (value interface {}, loaded bool ) read, _ := m.read.Load().(readOnly) e, ok := read.m[key] if !ok && read.amended { m.mu.Lock() read, _ = m.read.Load().(readOnly) e, ok = read.m[key] if !ok && read.amended { e, ok = m.dirty[key] delete (m.dirty, key) m.missLocked() } m.mu.Unlock() } if ok { return e.delete () } return nil , false } func (m *Map) Delete (key interface {}) m.LoadAndDelete(key) } func (e *entry) delete () (value interface {}, ok bool ) for { p := atomic.LoadPointer(&e.p) if p == nil || p == expunged { return nil , false } if atomic.CompareAndSwapPointer(&e.p, p, nil ) { return *(*interface {})(p), true } } }
Delete 方法也是先从 read 操作开始,因为不需要锁。
如果 read 中不存在,那么就需要从 dirty 中寻找这个项目。最终,如果项目存在就删除(将它的值标记为 nil)。如果项目不为 nil 或者没有被标记为 expunged,那么还可以把它的值返回。
Pool Pool指代一类建立池化对象的并发数据结构,由于Go自带垃圾回收机制,当需要保留一些创建耗时的对象(例如数据库链接等)时,我们一般会采用Pool的数据结构来存放。
Go标准库中提供了一个通用的Pool数据结构,sync.Pool。
sync.Pool sync.Pool 本身就是线程安全的,多个 goroutine 可以并发地调用它的方法存取对象,需要注意的是sync.Pool 不可在使用之后再复制使用。
sync.Pool提供了三个对外的方法:
New:
Pool struct 包含一个 New 字段,这个字段的类型是函数 func() interface{}。当调用 Pool 的 Get 方法从池中获取元素,没有更多的空闲元素可返回时,就会调用这个 New 方法来创建新的元素。如果你没有设置 New 字段,没有更多的空闲元素可返回时,Get 方法将返回 nil,表明当前没有可用的元素。
Get:
如果调用这个方法,就会从 Pool取走一个元素,这也就意味着,这个元素会从 Pool 中移除,返回给调用者。不过,除了返回值是正常实例化的元素,Get 方法的返回值还可能会是一个 nil(Pool.New 字段没有设置,又没有空闲元素可以返回) ,所以在使用的时候,可能需要判断。
Put
这个方法用于将一个元素返还给 Pool,Pool 会把这个元素保存到池中,并且可以复用。但如果 Put 一个 nil 值,Pool 就会忽略这个值。
典型使用场景,buffer池:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var buffers = sync.Pool{ New: func () interface return new (bytes.Buffer) }, } func GetBuffer () *bytes .Buffer return buffers.Get().(*bytes.Buffer) } func PutBuffer (buf *bytes.Buffer) if buf.Cap() > 1 <<16 { retrun } buf.Reset() buffers.Put(buf) }
sync.Pool内部实现 关于GC Go 1.1.3之前,sync.Pool实现有2大问题:
每次 GC 都会回收创建的对象。
如果缓存元素数量太多,就会导致 STW 耗时变长;缓存元素都被回收后,会导致 Get 命中率下降,Get 方法不得不新创建很多对象。
底层实现使用了 Mutex,对这个锁并发请求竞争激烈的时候,会导致性能的下降。
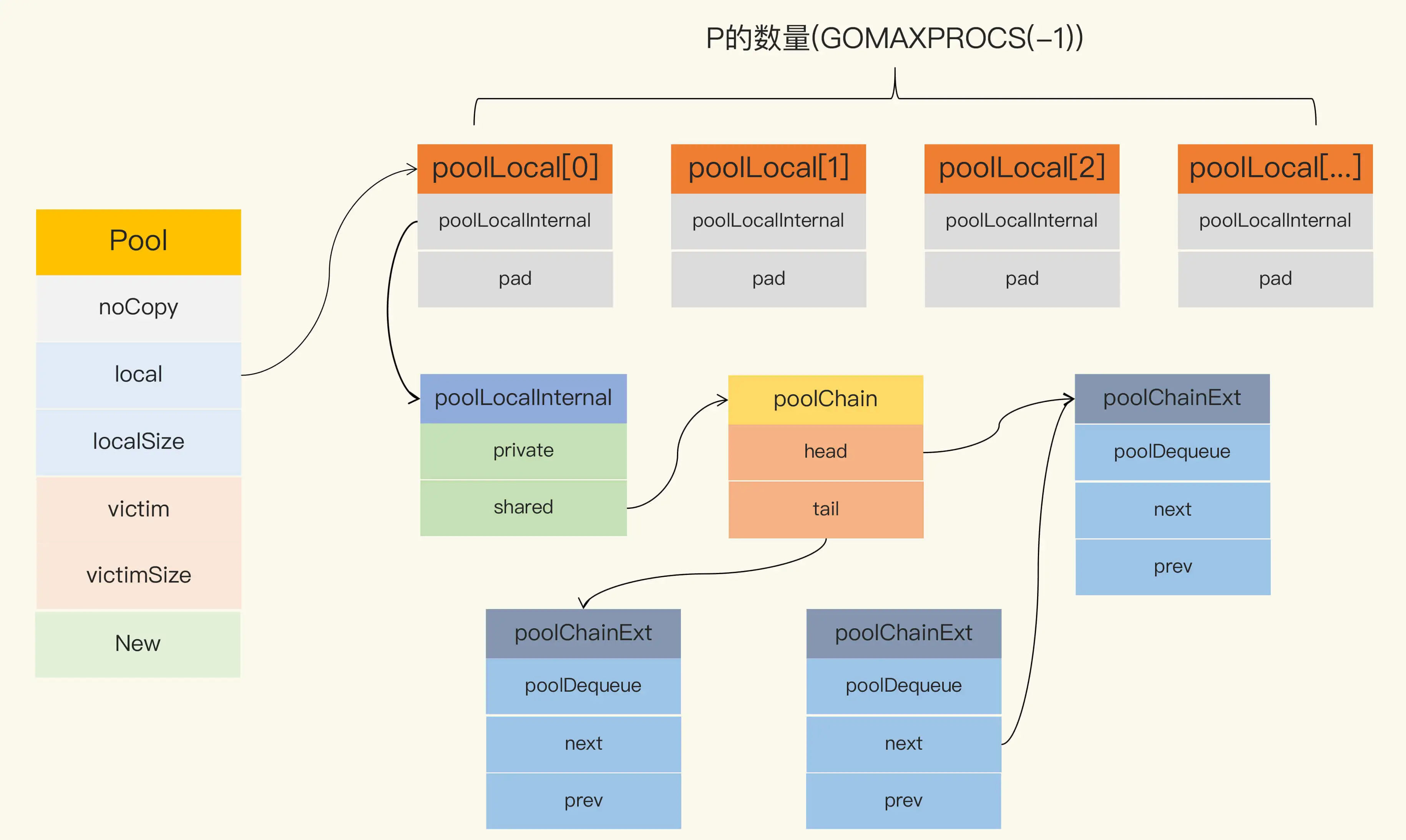
当前版本sync.Pool的数据结构如下:
Pool 最重要的两个字段是 local 和 victim,因为它们两个主要用来存储空闲的元素。
每次垃圾回收的时候,Pool 会把 victim 中的对象移除,然后把 local 的数据给 victim,这样的话,local 就会被清空,而 victim 就像一个垃圾分拣站,里面的东西可能会被当做垃圾丢弃了,但是里面有用的东西也可能被捡回来重新使用。
victim 中的元素如果被 Get 取走,那么这个元素就很幸运,因为它又“活”过来了 。但是,如果这个时候 Get 的并发不是很大,元素没有被 Get 取走,那么就会被移除掉,因为没有别人引用它的话,就会被垃圾回收掉。
GC时sync.Pool的处理逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func poolCleanup () for _, p := range oldPools { p.victim = nil p.victimSize = 0 } for _, p := range allPools { p.victim = p.local p.victimSize = p.localSize p.local = nil p.localSize = 0 } oldPools, allPools = allPools, nil }
在这段代码中,因为所有当前主要的空闲可用的元素都存放在 local 字段中,请求元素时也是优先从 local 字段中查找可用的元素。 local 字段包含一个 poolLocalInternal 字段,并提供 CPU 缓存对齐,从而避免 false sharing。
而 poolLocalInternal 也包含两个字段:private 和 shared。
private:代表一个缓存的元素,而且只能由相应的一个 P 存取。因为一个 P 同时只能执行一个 goroutine,所以不会有并发的问题。
shared:可以由任意的 P 访问,但是只有本地的 P 才能 pushHead/popHead,其它 P 可以 popTail,相当于只有一个本地的 P 作为生产者(Producer),多个 P 作为消费者(Consumer),它是使用一个 local-free 的 queue 列表实现的。
Get方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func (p *Pool) Get () interface l, pid := p.pin() x := l.private l.private = nil if x == nil { x, _ = l.shared.popHead() if x == nil { x = p.getSlow(pid) } } runtime_procUnpin() if x == nil && p.New != nil { x = p.New() } return x }
首先,从本地的 private 字段中获取可用元素,因为没有锁,获取元素的过程会非常快,如果没有获取到,就尝试从本地的 shared 获取一个,如果还没有,会使用 getSlow 方法去其它的 shared 中“偷”一个。最后,如果没有获取到,就尝试使用 New 函数创建一个新的。
这里的重点是 getSlow 方法,我们来分析下。看名字也就知道了,它的耗时可能比较长。它首先要遍历所有的 local,尝试从它们的 shared 弹出一个元素。如果还没找到一个,那么,就开始对 victim 下手了。
在 vintim 中查询可用元素的逻辑还是一样的,先从对应的 victim 的 private 查找,如果查不到,就再从其它 victim 的 shared 中查找。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 func (p *Pool) getSlow (pid int ) interface size := atomic.LoadUintptr(&p.localSize) locals := p.local for i := 0 ; i < int (size); i++ { l := indexLocal(locals, (pid+i+1 )%int (size)) if x, _ := l.shared.popTail(); x != nil { return x } } size = atomic.LoadUintptr(&p.victimSize) if uintptr (pid) >= size { return nil } locals = p.victim l := indexLocal(locals, pid) if x := l.private; x != nil { l.private = nil return x } for i := 0 ; i < int (size); i++ { l := indexLocal(locals, (pid+i)%int (size)) if x, _ := l.shared.popTail(); x != nil { return x } } atomic.StoreUintptr(&p.victimSize, 0 ) return nil }
Put方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 func (p *Pool) Put (x interface {}) if x == nil { return } l, _ := p.pin() if l.private == nil { l.private = x x = nil } if x != nil { l.shared.pushHead(x) } runtime_procUnpin() }
Put 的逻辑相对简单,优先设置本地 private,如果 private 字段已经有值了,那么就把此元素 push 到本地队列中。
连接池 由于sync.Pool 会无通知地在某个时候就把连接移除垃圾回收掉了,而我们需要长久保持这个连接时,一般会使用其它方法来池化连接。
http client 池 标准库的 http.Client 是一个 http client 的库,可以用它来访问 web 服务器。为了提高性能,这个 Client 的实现也是通过池的方法来缓存一定数量的连接,以便后续重用这些连接。
TCP 连接池 最常用的一个 TCP 连接池是 fatih 开发的fatih/pool ,虽然这个项目已经被 fatih 归档(Archived),不再维护了,但是因为它相当稳定了,我们可以开箱即用。即使你有一些特殊的需求,也可以 fork 它,然后自己再做修改。
它通过把 net.Conn 包装成 PoolConn,实现了拦截 net.Conn 的 Close 方法,避免了真正地关闭底层连接,而是把这个连接放回到池中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 type PoolConn struct { net.Conn mu sync.RWMutex c *channelPool unusable bool } //拦截Close func (p *PoolConn) Close() error { p.mu.RLock() defer p.mu.RUnlock() if p.unusable { if p.Conn != nil { return p.Conn.Close() } return nil } return p.c.put(p.Conn) }
数据库连接池 标准库 sql.DB 还提供了一个通用的数据库的连接池,通过 MaxOpenConns 和 MaxIdleConns 控制最大的连接数和最大的 idle 的连接数。默认的 MaxIdleConns 是 2,这个数对于数据库相关的应用来说太小了,我们一般都会调整它。
Worker Pool 大量的goroutine会导致无效的调度和垃圾回收,为了防止goroutine溢出等情况,有时候我们需要创建Worker Pool来控制goroutine的数量。
常用的Worker Pool三方库推荐:
gammazero/workerpool :gammazero/workerpool 可以无限制地提交任务,提供了更便利的 Submit 和 SubmitWait 方法提交任务,还可以提供当前的 worker 数和任务数以及关闭 Pool 的功能。
ivpusic/grpool :grpool 创建 Pool 的时候需要提供 Worker 的数量和等待执行的任务的最大数量,任务的提交是直接往 Channel 放入任务。
dpaks/goworkers :dpaks/goworkers 提供了更便利的 Submit 方法提交任务以及 Worker 数、任务数等查询方法、关闭 Pool 的方法。它的任务的执行结果需要在 ResultChan 和 ErrChan 中去获取,没有提供阻塞的方法,但是它可以在初始化的时候设置 Worker 的数量和任务数。
Context Context的出现主要为了解决goroutine的控制以及goroutine间的上下文信息传递(如认证信息、环境信息等)。
Context基本用法 1 2 3 4 5 6 type Context interface { Deadline() (deadline time.Time, ok bool ) Done() <-chan struct {} Err() error Value(key interface {}) interface {} }
Deadline: Deadline 方法会返回这个 Context 被取消的截止日期。如果没有设置截止日期,ok 的值是 false。后续每次调用这个对象的 Deadline 方法时,都会返回和第一次调用相同的结果。
Done: Done 方法返回一个 Channel 对象。在 Context 被取消时,此 Channel 会被 close,如果没被取消,可能会返回 nil。后续的 Done 调用总是返回相同的结果。当 Done 被 close 的时候,你可以通过 ctx.Err 获取错误信息。
Err: 如果 Done 没有被 close,Err 方法返回 nil;如果 Done 被 close,Err 方法会返回 Done 被 close 的原因。
Value: 返回此 ctx 中和指定的 key 相关联的 value。
Context 中实现了 2 个常用的生成顶层 Context 的方法:
context.Background(): 返回一个非 nil 的、空的 Context,没有任何值,不会被 cancel,不会超时,没有截止日期。一般用在主函数、初始化、测试以及创建根 Context 的时候。
context.TODO(): 返回一个非 nil 的、空的 Context,没有任何值,不会被 cancel,不会超时,没有截止日期。当你不清楚是否该用 Context,或者目前还不知道要传递一些什么上下文信息的时候,就可以使用这个方法。
在使用 Context 的时候,有一些约定俗成的规则:
一般函数使用 Context 的时候,会把这个参数放在第一个参数的位置。
从来不把 nil 当做 Context 类型的参数值,可以使用 context.Background() 创建一个空的上下文对象,也不要使用 nil。
Context 只用来临时做函数之间的上下文透传,不能持久化 Context 或者把 Context 长久保存。把 Context 持久化到数据库、本地文件或者全局变量、缓存中都是错误的用法。
key 的类型不应该是字符串类型或者其它内建类型,否则容易在包之间使用 Context 时候产生冲突。
使用 WithValue 时,key 的类型应该是自己定义的类型。常常使用 struct{}作为底层类型定义 key 的类型。对于 exported key 的静态类型,常常是接口或者指针。这样可以尽量减少内存分配。
我们一般使用Context时,会采用WithValue、WithCancel、WithTimeout 和 WithDeadline :
WithValue WithValue 基于 parent Context 生成一个新的 Context,保存了一个 key-value 键值对。它常常用来传递上下文,Context实现了链式查找,如果当前context不包含所查找的key,会像parent Context中去查找。
1 2 3 4 5 6 7 ctx = context.TODO() ctx = context.WithValue(ctx, "key1" , "0001" ) ctx = context.WithValue(ctx, "key2" , "0001" ) ctx = context.WithValue(ctx, "key3" , "0001" ) ctx = context.WithValue(ctx, "key4" , "0004" ) fmt.Println(ctx.Value("key1" ))
example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 var key string ="name" func main () ctx, cancel := context.WithCancel(context.Background()) valueCtx:=context.WithValue(ctx,key,"【监控1】" ) go watch(valueCtx) time.Sleep(10 * time.Second) fmt.Println("可以了,通知监控停止" ) cancel() time.Sleep(5 * time.Second) } func watch (ctx context.Context) for { select { case <-ctx.Done(): fmt.Println(ctx.Value(key),"监控退出,停止了..." ) return default : fmt.Println(ctx.Value(key),"goroutine监控中..." ) time.Sleep(2 * time.Second) } } }
WithCanel\withDeadline\withTimeout 1 2 3 4 func WithCancel (parent Context) (ctx Context, cancel CancelFunc) func WithDeadline (parent Context, deadline time.Time) (Context, CancelFunc) func WithTimeout (parent Context, timeout time.Duration) (Context, CancelFunc) func WithValue (parent Context, key, val interface {}) Context
WitchCancel传递一个父Context作为参数,返回子Context,以及一个取消函数用来取消Context。 WithDeadline函数,和WithCancel差不多,它会多传递一个截止时间参数,意味着到了这个时间点,会自动取消Context,当然我们也可以不等到这个时候,可以提前通过取消函数进行取消。
WithTimeout和WithDeadline基本上一样,这个表示是超时自动取消,是多少时间后自动取消Context的意思。
WithCancel方法实现:
1 2 3 4 5 6 7 8 9 10 func WithCancel (parent Context) (ctx Context, cancel CancelFunc) c := newCancelCtx(parent) propagateCancel(parent, &c) return &c, func () true , Canceled) } } func newCancelCtx (parent Context) cancelCtx return cancelCtx{Context: parent} }
Cancel 是向下传递的,如果一个 WithCancel 生成的 Context 被 cancel 时,如果它的子 Context(也有可能是孙,或者更低,依赖子的类型)也是 cancelCtx 类型的,就会被 cancel,但是不会向上传递。parent Context 不会因为子 Context 被 cancel 而 cancel。
WithCancel示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func main () ctx, cancel := context.WithCancel(context.Background()) go watch(ctx,"【监控1】" ) go watch(ctx,"【监控2】" ) go watch(ctx,"【监控3】" ) time.Sleep(10 * time.Second) fmt.Println("可以了,通知监控停止" ) cancel() time.Sleep(5 * time.Second) } func watch (ctx context.Context, name string ) for { select { case <-ctx.Done(): fmt.Println(name,"监控退出,停止了..." ) return default : fmt.Println(name,"goroutine监控中..." ) time.Sleep(2 * time.Second) } } }